EMC VNX Snapview not supported with AIX MPIO
I found that some customers uses SnapView on CX or VNX Flare with AIX native MPIO driver on VIOS or AIX.
Already in 2008, EMC wrote a technical note specifying that software layered like Snapview was not supported with AIX MPIO.
Technote: 300-008-486_aix_native_mpio_clariion_1108
Today, this technote has disappeared but EMC support write a EMC primus "emc75601" specify that it is still not supported with VNX software layered.
Driver Example :
EMC.CLARiiON.fcp.MPIO.rte 5.3.0.8 C F EMC CLARiiON FCP MPIO Support
devices.common.IBM.mpio.rte 6.1.7.15 C F MPIO Disk Path Control Module
EMC primus case "emc75601"
EMC Layered software such as SnapView, MirrorView/Asynchronous, MirrorView/Synchronous,
EMC SAN Copy, etc., are not supported with hosts running AIX Native MPIO
So if it is imperative to use Snapview, then install EMC PowerPath.
Tips for implementing NPIV on IBM Power Systems
IBM India Lab write a excelent document on configuring NPIV :
Power Systems SAN Multipath Configuration Using NPIV v1.2
Chris Gibson shares some tips for implementing NPIV in an AIX and Virtual I/O Server environment on IBM POWER7 systems.
Tips for implementing NPIV on IBM Power Systems
Thank's Chris.
Other NPIV source :
NPIV and the virtual I/O server 2008
IBM PowerVM Virtualization managing and monitoring
IBM PowerVM Virtualization Introduction and Configuration

How to Capture SAN Boot Debug for Virtual I/O Server and AIX on P6 Systems
Problem(Abstract)
How to capture boot debug of a SAN boot PowerVM Virtual I/O Server or AIX/NPIV client partition that is failing to boot.
Symptom
NPIV/AIX Client or VIOS fails to boot from SAN.
Environment
REQUIREMENTS
1. POWER6 System
2. A program where console terminal logging can be enabled will be needed. The following procedure uses PuTTY (a Windows ssh client program) as the means to open a console session to capture the boot debug data to a file. It's available for download at http://www.putty.org
Diagnosing the problem
Things to check PRIOR to gathering the debug
For a NEW NPIV/AIX Client Install
1. Ensure NPIV mapping is correct
2. Ensure SAN swtich is zoned correctly to the NPIV client's WWPN
3. Ensure resources (LUN) is assigned from the storage directly to the client's WWPN
4. Ensure Installation media meet minimum level required by the storage
For previously running LPAR
1. Check if boot device can be set in SMS
2. Check if rootvg is accessible in Service Mode.
Resolving the problem
1. To capture a boot debug to a file, open an ssh session via PuTTY to the HMC as follows
Under Category
Session
-> click on Logging
-> select "All session output" on the right
-> specify the filename in the "Log file name" box as shown in Figure 1
Terminal
-> click on Keyboard
-> select Control-H for the Backspace key
Click on Session
-> Type in the full domain to the HMC in the Host Name and Saved Sessions box
-> select SSH protocol (HMC must be configured to accept ssh connections)
-> Click on Open (See Figure 2). You will get a PuTTY Security Alert Window
-> Click No to connect just once
-> Login as hscroot and type 'vtmenu' to open a console session to the partition in question
-> Select the Managed System name
-> Select the partition in question =>You may or may not see activity at this point depending on the status of the partition.
2. Boot the partition to Open Firmware (0 >) prompt, run ioinfo utility, and select the FCINFO option as follows:
!!! IOINFO: FOR IBM INTERNAL USE ONLY !!!
This tool gives you information about SCSI,IDE,SATA,SAS,and USB devices attached to the
system
Select a tool from the following
1. SCSIINFO
2. IDEINFO
3. SATAINFO
4. SASINFO
5. USBINFO
6. FCINFO <=====
7. VSCSIINFO
q - quit/exit
==> 6
3. Select the desired path. In this example, we are selected the 2nd virtual Fibre Channel path:
FCINFO Main Menu
Select a FC Node from the following list:
---------------------------------------------------------------
1. U9117.MMA.65EBF8C-V32-C5-T1 /vdevice/vfc-client@30000005
2. U9117.MMA.65EBF8C-V32-C6-T1 /vdevice/vfc-client@30000006
q - Quit/Exit
==> 2
4. Select a FC Device
FC Node String: /vdevice/vfc-client@30000006
FC Node WorldWidePortName: c05076001ab6003a
-----------------------------------------------------------------
1. List Attached FC Devices
2. Select a FC Device <=====
3. Enable/Disable FC Adapter Debug flags
q - Quit/Exit
==> 2
5. Select the appropriate LUN. In this example option 1 happens to be the bootable device:
2. 50060e801530f310,1000000000000 - 35840 MB Disk drive
Select a FC Device : 1
FC Device Menu
FC Target Address ==> 50060e801530f310 FC Lun Address ==> 0
FC Device String: /vdevice/vfc-client@30000006/disk@50060e801530f310,0:0
FC Device: 10240 MB Disk drive (bootable)
----------------------------------------------------------------------
6. Select "Display Inquiry Data"
2. Spin up Drive
3. Spin down Drive
4. Continuous random Reads ( hit any key to stop )
5. Enable/Disable FC Device Debug flags
98. Boot from this Device
q - Quit/Exit
==> 1
INQUIRY DATA FOR : TARGET ==> 50060e801530f310
LUN ==> 0 - 10240 MB Disk drive (bootable)
000002f4cd00: 00 00 03 32 cf 00 00 02 48 49 54 41 43 48 49 20 :...2....HITACHI :
000002f4cd10: 4f 50 45 4e 2d 56 20 20 20 20 20 20 20 20 20 20 :OPEN-V :
000002f4cd20: 36 30 30 34 35 30 20 31 33 30 46 33 33 30 33 33 :600450 130F33033:
000002f4cd30: 20 32 41 20 01 01 01 01 00 00 00 00 00 00 00 00 : 2A ............:
000002f4cd40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :................:
000002f4cd50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :................:
000002f4cd60: 05 01 05 70 30 30 ff 00 c0 50 76 00 1a b6 00 3a :...p00...Pv....::
000002f4cd70: c0 50 76 00 1a b6 00 3a 00 00 00 0f 00 00 00 00 :.Pv....:........:
000002f4cd80: 00 00 00 00 00 00 00 00 00 00 00 00 00 03 00 00 :................:
000002f4cd90: 01 01 01 01 00 00 00 00 01 01 01 01 01 01 01 01 :................:
000002f4cda0: 01 01 01 01 01 01 01 01 55 55 55 55 55 55 55 55 :........UUUUUUUU:
000002f4cdb0: 55 55 55 55 00 00 00 00 ff ff ff ff 00 00 00 00 :UUUU............:
000002f4cdc0: 00 00 00 03 00 00 00 01 00 00 00 01 00 01 99 40 :...............@:
000002f4cdd0: 00 00 71 a3 00 00 00 00 00 00 00 00 00 00 00 00 :..q.............:
000002f4cde0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :................:
000002f4cdf0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :...............:
Hit a key to continue...
FC Device Menu
FC Target Address ==> 50060e801530f310 FC Lun Address ==> 0
FC Device String: /vdevice/vfc-client@30000006/disk@50060e801530f310,0:0
FC Device: 10240 MB Disk drive (bootable)
----------------------------------------------------------------------
7. Select to "Boot from this Device"
2. Spin up Drive
3. Spin down Drive
4. Continuous random Reads ( hit any key to stop )
5. Enable/Disable FC Device Debug flags
98. Boot from this Device
q - Quit/Exit
==> 98
----------------------------------------------------------------------
Welcome to AIX.
boot image timestamp: 06:26 10/01
The current time and date: 09:46:20 10/01/2009
processor count: 1; memory size: 8192MB; kernel size: 23463042
boot device: /vdevice/vfc-client@30000006/disk@50060e801530f310,0
-----------------------------------------------------------------------
SAN Switch Replacement in AIX Environments
Abstract: The purpose of this document is to describe the concepts and procedures used to replace SAN switches in an AIX Power environment. This includes direct attached or VIO attached storage, and with VIO both the VSCSI and NPIV cases. The article will first discuss dynamic tracking as this is important for making SAN changes. Then we'll look at SAN switch replacement in direct attached storage, VIO VSCSI attached storage, and VIO NPIV attached storage environments, including single SAN fabric and dual SAN fabric environments. We'll examine this from an MPIO environment, and consider how this applies to other multi-path code last.
SAN Switch Replacement in AIX Environments
Overview
The purpose of this document is to describe the concepts and procedures used to replace SAN switches in an AIX Power environment. This includes direct attached or VIO attached storage, and with VIO both the VSCSI and NPIV cases. The article will first discuss dynamic tracking as this is important for making SAN changes. Then we'll look at SAN switch replacement in direct attached storage, VIO VSCSI attached storage, and VIO NPIV attached storage environments, including single SAN fabric and dual SAN fabric environments. We'll examine this from an MPIO environment, and consider how this applies to other multi-path code last.
Dynamic tracking and LUN configuration
In environments with SAN switches, one will normally want to set certain attributes for the fscsi devices, specifically the dyntrk and fc_err_recov attributes. By default, these are set to no and delayed_fail respectively and assume the server is not attached to a SAN switch. This is important because the procedures to replace a switch are quite different depending on these settings.
Without dyntrk=yes, you will have to remove disk devices and reconfigure them. This means that any hdisk attribute settings you have changed will be undone, and you'll have to change them again. With dyntrk=yes, you do not have to remove the hdisk device definitions and you won't lose changes to the disk attributes. Disk attributes that are often changed include the reserve_policy for SCSI reserves, and the queue_depth for performance.
Here's how to look at these attributes:
attach switch How this adapter is CONNECTED False
dyntrk no Dynamic Tracking of FC Devices True
fc_err_recov delayed_fail FC Fabric Event Error RECOVERY Policy True
scsi_id 0x10000 Adapter SCSI ID False
sw_fc_class 3 FC Class for Fabric True
You should set these as follows:
dyntrk=yes
fc_err_recov=fast_fail
via this command if no disks are in use:
or if the disks are in use:
and then reboot to make the changes go into effect. Thus, these changes are not dynamic for the LPAR. Preferably they attributes are set as recommended when the LPAR is installed and setup.
Note that at VIOSs (VIO Servers) if a LUN is mapped from the VIOS to a VIOC (VIO Client) as a VSCSI disk, then the disk is in use, even if the VIOC isn't using the disks. So in a typical dual VIOS environment, one would make this change to one VIOS, reboot it, then make the change to the other VIOS and reboot it.
Lacking these attribute settings, AIX includes information about the specific port on the switch, as part of the LUN configuration. Thus, to use a different port on the switch or another switch entirely, one will have to actually remove the disk definition (via a # rmdev -dl
For more details on these settings see the documentation at :
http://www-1.ibm.com/support/docview.wss?uid=isg1520readmefb4520desr_lpp_bos
Can SAN switch replacements be done dynamically?
Provided the dyntrk and fc_err_recov are properly set, the answer is yes provided one ensures that there will always be at least one working path for each hdisk. Additionally, in some cases with only one path, provided we move the cable fast enough, then we can also do this dynamically; however this is discouraged. Fast enough is such that from the time we unplug a cable from a switch port, plug it into a port on the new switch, plus the time for the SAN fabric to recognize the new cabling, is less than 15 seconds so the IOs don't time out and fail. So when one path to the disk exists, SAN switch replacements are preferably done during maintenance windows. For example, if a cable isn't properly seated or a port is defective, then IOs can fail leading to problems.
Know your paths and the cables they use
As the previous paragraph makes clear, you want to make sure that a working path exists when dynamically migrating from one SAN switch to another. So you need to know what paths exist to your disks and the cables involved. To that end, it's important to understand that a path is uniquely described via the host port and the storage port used by the path, and that ports are uniquely identified via a WWPN (World Wide Port Name) which is 16 digits. How one determines this depends on the multi-path code used for the storage, and this article initially focuses on MPIO environments (which includes storage using SDDPCM as the multi-path code since SDDPCM uses MPIO under the covers). To list the paths for your disks with MPIO, use the lspath command as follows (here for hdisk2):
hdisk2 Enabled fscsi0 203900a0b8478dda,f00000000000 Available
hdisk2 Enabled fscsi0 201800a0b8478dda,f00000000000 Available
hdisk2 Enabled fscsi1 201800a0b8478dda,f00000000000 Available
hdisk2 Enabled fscsi1 203900a0b8478dda,f00000000000 Available
This shows hdisk2 has 4 paths, two from fcs0 (the parent device of fscsi0) two from fcs1, and going to two separate ports on the storage and identified via the WWPN of the storage port: 203900a0b848dda or 20180a0b8478dda. From this we can also conclude that we're only using one SAN fabric for this LUN (and probably for the LPAR as well - and this can be verified by looking at the paths for all LUNs and in which case they'd look similar) since both host ports connect to both storage ports. Thus, the cabling would look like:
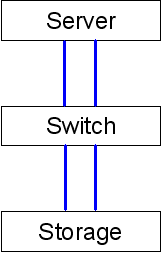
In VIO VSCSI environments, you'd run the lspath commands on the VIOS (VIO Server) in the oem_setup_env shell, as we're concerned about paths from the VIOS to the storage. In a VIO NPIV environment, one would run the lspath commands on the VIOC plus one will need to know the vFC to real FC adapter mapping
Identifying adapter and port locations
It will be important to know which cables connect to which ports on the storage, host. and SAN switches. Since this document discusses SAN switch replacement, perhaps the easiest method is to obtain the host and storage WWPNs for the ports and then from the switch management interface, determine the ports to which they are connected. From the host side, you can list the port location code and WWPN via the following command:

Or for a description of the adapter and its location code:
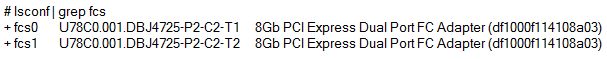
These are a dual port adapters, and checking the Finding Parts Locations and Addresses manual for the specific system model (these manuals are available in the Power Hardware Information Center at http://publib.boulder.ibm.com/infocenter/powersys/v3r1m5/index.jsp) one can determine the specific slot location for the adapter. In this case the system model is a 9179-MHB and the P2-C2 in the location field indicates that the adapter is in slot 2 of the system unit. Then T1 refers to the top port and T2 to the bottom port. These adapters also have an identify light, so one can go into the diagnostics menu and get the light to flash to more easily locate the adapter.
Also note that it is possible that the fcs0 and fscsi0 don't refer to the same port, so you can't rely on the numbers for the devices. You can see the relationship via the location codes, e.g.:

This shows fcs0 is related to fscsi0 via the location codes.
Be aware if you are you using an active/passive disk subsystem
An active/passive disk subsystem is one in which one controller of a pair is used to handle all IOs to a LUN except in failure conditions. Examples of active/passive IBM storage include the DS3000, DS4000, DS5000, SVC and Storwize V7000. The reason this is important, is that it's preferable to not lose access to the primary controller for the LUNs during a switch replacement, or to at least be aware that LUNs will switch controllers if all paths to the primary controller are lost during the switch replacement. Usually half the LUNs have one storage controller as the preferred controller, with the other half of the LUNs using the other controller. So if only one cable is used per controller, this means that LUNs will fail over to the other controller if the server is doing IOs to the storage during the switch replacement.
It's also possible to use RDAC for DS4000 storage which requires that host adapterA is connected to storage controllerA, and host adapterB is connected to storage controllerB, without any cross connections. Please be aware that from AIX 6.1 and on, MPIO is strategic and preferred. One can choose the multi-path code used for the DS3/4/5000 via the manage_disk_drivers command available in AIX (note that there are also requirements from the storage side for MPIO).
Later when all paths are restored, one will normally want the storage administrator to switch the LUN back to the preferred controller. If all paths to one controller will be lost during a switch replacement, then it's recommended that the storage administrator move all IO handling to the controller that will be accessible prior to moving a cable.
Should you use ISLs to facilitate SAN switch replacement?
Connecting two switches via Inter Switch Links (ISLs) joins two switches into a fabric. Before going into ISLs, it's important to know that one should have dynamic tracking enabled prior to adding a switch to a fabric via an ISL as lacking that setting might cause IOs to be lost.

In the case where we have ISLs, we can move the cables in any order, and provided we do so quickly enough and we properly seat the cables, IOs will be slightly delayed. For the non-ISL environment, we have to use more care. First, we can't move the cables in any order. We have to move a server cable, then a storage cable; otherwise, the server will lose access to the storage. When we move cable E, any IOs using that cable will fail, and we'll have to rely on the multi-path code at the server to redirect the IO to use cable F. This delay will be longer as the IO must time out. If we move cable G first, and fc_err_recov=fast_fail and the switch supports fast fail, then the switch will inform the adapter driver that the port no longer has access to the storage and the multi-path code will immediately redirect the IOs to use cable H, so this will be less delay than if moving a server side cable.
Of course, if we stop the application and IOs, then we can move the cables without worrying about doing it quickly or regarding the order cables are moved. So we can see that ISLs facilitate switch replacement here, though the option of stopping IO entirely avoids some of the work required.
Why it's better to disable paths prior to cable movement
While we can use the path availability facilities to handle lost paths during a switch replacement, it's preferable to disable paths prior to moving cables for two reasons. First, in-flight IOs will be delayed if we don't disable the paths first. This delay might result in the application stalling while IOs time out and re-initiated down available paths, or with active/passive disk subsystems, while the storage moves IO processing from one controller to another. Secondly, and perhaps more importantly, bugs in the recovery portions of the code might have bugs which could result in IO failures. Given the matrix of multi-path code versions, storage firmware/microcode, and adapter firmware, it's difficult to test all possible combinations of code and failures. If you've tested path failure, observing failure detection, handling of IOs in-flight, and path recovery, then one can be assured that the code will work correctly.
How to disable and re-enable paths
The command to disable or enable paths for IO is the chpath command, e.g.:
VIO VSCSI environments
Here are two diagrams of a VIO Client (VIOC) using VSCSI to access SAN attached storage through a pair of VIO Servers (VIOSs) in a dual SAN fabric environment showing two cabling strategies:

It's important to realize there are 2 layers of multi-path code here. MPIO is always used at the VIOC for choosing a path to the VIOSs. The multi-path code at the VIOS depends on what the storage requires. From the VIOC, each LUN has two paths (to each VIOS). From the VIOS, there are potentially 8 paths to a LUN in example 1, and potentially 4 paths to a LUN for example 2. Besides having more paths, there is an availability difference between the two diagrams. Example 1 can continue running with the failure of a VIOS and a SAN fabric. Example 2 can also, provided the right pair of VIOS and fabric fail. Thus, typically you'll see cabling similar to the diagram on the left.
A difference in how one would disable paths here exists. For example 1, when replacing a switch, one preferably disables/enables paths at the VIOSs when replacing a switch. For example 2, one can simply disable the paths to the VIOS attached to the switch being replaced. And one can just disable all paths for a fibre channel port attached to the SAN switch being replaced, if the multi-path code provides this capability.
VIO NPIV environments
Here are two examples of a VIOC using NPIV thru two VIOSs in a dual SAN fabric to access SAN attached storage:

Here there is only one layer of multi-path code, and that is in the VIOC. In both examples, there are 8 potential paths per LUN. However example 3 has superior availability characteristics in that we can have a VIOS fail and a SAN fabric failure without losing access to the storage, while in example 4 we could lose access if a VIOS and the SAN fabric the other VIOS uses fails. So all path management commands are done from the VIOC. And in both cases one can just disable all paths for a fibre channel port attached to the SAN switch being replaced, if the multi-path code provides this capability.
Multi-path code other than MPIO
There are other multi-path code sets besides MPIO, and often MPIO isn't a choice as the storage vendor dictates what must be used for their storage, and MPIO is often not an option. Each multi-path code set has its own command for handling path management, and the concepts previously mentioned still apply.
For example, one can use SDDPCM (which is compliant with the MPIO architecture) and still use the MPIO commands; however, you may find using the pcmpath command to be easier to accomplish your objectives. SDD is another multi-path code set from IBM (though SDDPCM is strategic) and one can use the datapath command for path management. PowerPath is a common option for customers attaching EMC storage to Power, in which case one typically uses the powermt command for path management.
SOURCE: IBM TD105839
Recover switch password IBM 2109-F32 (SilkWorm 3900)
1. Connect the serial cable to the serial port on the switch and to an RS-232
Use the PBRU cable ![]()
- Cisco cable DB9/RJ45 (72-3383-01) + SUN connector RJ45/DB9 (530-3100-01)
2. Poweron the IBM 2109-F32 Switch
3. Press ESC at the message “Press escape within 4 seconds...” The Boot PROM menu is displayed with the following options:
- 1) Start system.
Used to reboot the system.
- 2) Recover password.
Used to generate a character string for your support provider to recover the Boot PROM password.
- 3) Enter command shell.
Used to enter the command shell, to reset all passwords on the system.
4. Type 3 at the prompt to open the command shell.
5. Type the Boot PROM password, if prompted, then press Enter. The Boot PROM has a password only if one was defined earlier.
6. Run the printenv command, then save the output to a file. You will need to refer to this output later in the procedure.
7. Locate the first memory address; it is the string after OSLoader= in the printenv output.
8. Run the boot command with the first memory address and the –s option. For example:
9. For a SilkWorm 200E, 3250, 3850, 3900, 4100, 4900, or 7500 switch, perform the following steps:
a. Enter the mount command with the following parameters:
> mount -o remount,rw,noatime /
This will remount the root partition as read/write.
b. Enter the mount command with the following parameters where hda is followed by the second partition value
(such as 1 or 2) from OSRootPartition in the printenv output:
> mount /dev/hda2 /mnt
c. Enter the passwddefault command, as follows:
> /sbin/passwddefault
This resets all account passwords to the default values. If there were additional user accounts created, they are deleted and only the default accounts and passwords remain.
d. Reboot the switch using the reboot –f command.
> reboot -f
Example:
Checking system RAM - press any key to stop test
System RAM check terminated by keyboard
System RAM check complete
Press escape within 4 seconds to enter boot interface.
1) Start system.
2) Recover password.
3) Enter command shell.
Option? 3
Password:password
> printenv
AutoLoad=yes
ENET_MAC=006069901998
InitTest=MEM()
LoadIdentifiers=Fabric Operating System;Fabric Operating System
OSBooted=MEM()0xF0000000
OSLoadOptions=quiet;quiet
OSLoader=MEM()0xF0000000;MEM()0xF0800000
OSRootPartition=hda1;hda2
SkipWatchdog=yes
> boot MEM()0xF0000000 -s
Booting "Manually selected OS" image.
Entry point at 0x00800000 ...
Linux/PPC load:
BootROM command line: -s
Uncompressing Linux...done.
Now booting the kernel
Linux version 2.4.19 (swrel@elixir) (gcc version 2.95.3 20010112 (prerelease)) -n #1 Tue Oct 3 20:52:01 PDT 2006
.............
INIT: version 2.78 booting
sh-2.04# mount -o remount,rw,noatime /
sh-2.04# mount /dev/hda2 /mnt
XFS mounting filesystem ide0(3,2)
sh-2.04# /sbin/passwddefault
All account passwords have been successfully set to factory default.
sh-2.04# reboot -f
flushing ide devices: hda
Restarting system.
<NULL>
Normal reboot
Checking system RAM - press any key to stop test
System RAM check terminated by keyboard
System RAM check complete
Press escape within 4 seconds to enter boot interface.
Booting "Fabric Operating System" image.
Entry point at 0x00800000 ...
Linux/PPC load:
BootROM command line: quiet
Uncompressing Linux...done.
Now booting the kernel
Attempting to find a root file system on hda1...
INIT: version 2.78 booting
INIT: Entering runlevel: 3
eth0: Link status change: Link Up. 100 Mbps Full duplex Auto (autonegotiation complete).
Fabric OS (2109-F32)
2109-F32 console login: uptime: 2468; sysc_qid: 0
2011/09/06-16:35:30, [HAM-1004], 200,, INFO, Silkworm3900, Processor rebooted - Reboot
Fabric OS (2109-F32)
Fabos Version 5.2.0a
The administrative login is admin, and the default password is password.
Now, You can change default password for all user account.
Password:password
Please change passwords for switch default accounts now.
Use Control-C to exit or press 'Enter' key to proceed.
Warning: Access to the Root and Factory accounts may be required for
proper support of the switch. Please ensure the Root and Factory
passwords are documented in a secure location. Recovery of a lost Root
or Factory password will result in fabric downtime.
for user - root
Changing password for root
Enter new password:
Re-type new password:
passwd: all authentication tokens updated successfully
Please change passwords for switch default accounts now.
for user - factory
Changing password for factory
Enter new password:
Re-type new password:
passwd: all authentication tokens updated successfully
Please change passwords for switch default accounts now.
for user - admin
Changing password for admin
Enter new password:
Re-type new password:
passwd: all authentication tokens updated successfully
Please change passwords for switch default accounts now.
for user - user
Changing password for user
Enter new password:
Re-type new password:
passwd: all authentication tokens updated successfully
Saving passwords to stable storage.
Passwords saved to stable storage successfully
2109-F32:admin>
Catégories
- AIX
- AZURE
- BULL SYSTEM
- CEPH
- GLUSTER
- HACMP
- HMC
- IBM SYSTEM
- KUBERNETES
- LINUX
- NAS
- NIM
- Non classé
- OPENSHIFT
- ORACLE
- PERFORMANCE
- SAN
- TSM
- VIDEOS
- VIRTUAL I/O SERVER
Liens
- AIX Hiper APARs
- AIX Open Source Packages
- Awesome Kubernetes
- IBM AIX developerworks
- IBM Fix Central
- IBM HTTP Server
- IBM Power Bulletins
- IBM Redbooks
- Infocenter AIX 6.1
- Infocenter AIX 7.1
- Infocenter AIX5L
- Infocenter TSM 6.3
- SQL for Tivoli Storage Manager
- The Django Book
- TSM admin
- TSM Wiki
Tag Cloud
WP Cumulus Flash tag cloud by Roy Tanck requires Flash Player 9 or better.
Visiteurs
